深度神经网络中的梯度泄露问题
寒假摸鱼摸久了,才想起来年初是要找学姐交差的,要是再没有进展,估计明年的论文就没戏了。遂起身,爬下床,打开电脑开始看论文。
过年这几天虽然没少玩,但是也没少反思自己。觉得自己现在的成绩并不是完全没有原因的。尽管对外会说来到了顶级学府,身边多了更多了优秀的伙伴和竞争对手。但是我自己的内心知道,所谓鲶鱼效应,只有竞争才能激发自己的潜能。鄙人不才,但却自认为潜能远远没有开发完全。更多的时候,我因为个人性格的原因,会经常想得很多,喜欢漫无目的地乱走。但大家都知道,如果以路灯为起点,漫无目的地乱走,最终的期望就是回到终点。2021一整年对于我来说过得并不是很好。在这个同龄人在不断进步的时代,仿佛逆水行舟,不进则退。
但是每个人都会经历这样一段经历吧,人生的极小值点。所以对我来说,接下来的2022年,有一些确定的目标和计划就成为了迫在眉睫的事情。我相信自己的能力,从来都是如此。从科研方向来说,我还是得要在寒假期间,最起码需要了解梯度泄露是怎么回事,并且复现出代码。剩下的我想要看完吴恩达的机器学习课程,并且对于深度学习的花园书有所了解。争取在春季学期进行1-2个论文项目的参与。必须要在大三之前有所收获。
那么我们就进入正题。
Abstract
首先作者告诉我们,在分布式训练或者协作训练中,梯度的共享是一件很正常的事。人们通常也很放心地认为梯度并不会泄露分布的训练数据。但是这篇文章用极其大胆的猜想和实验的佐证(包括\(NLP\)和图像处理的两个实验都得到了非常好的效果)告诉我们梯度共享也有可能会泄露用户数据,并且称之为\(Deep \ Leakage \ from \ Gradients\)。并且指出了以梯度剪枝\((gradients \ pruning)\)为首的一些防御方法。
Introduction
首先作者指出,已经有研究表明,梯度的共享会泄露一些\(properties \ of \ training \ data\), 结合\(GAN\)就可以生成和原图像相似的图片。但是作者给出的DLG方法则声称可以还原完整的数据和标签,甚至不用借助任何其他的生成网络模型。
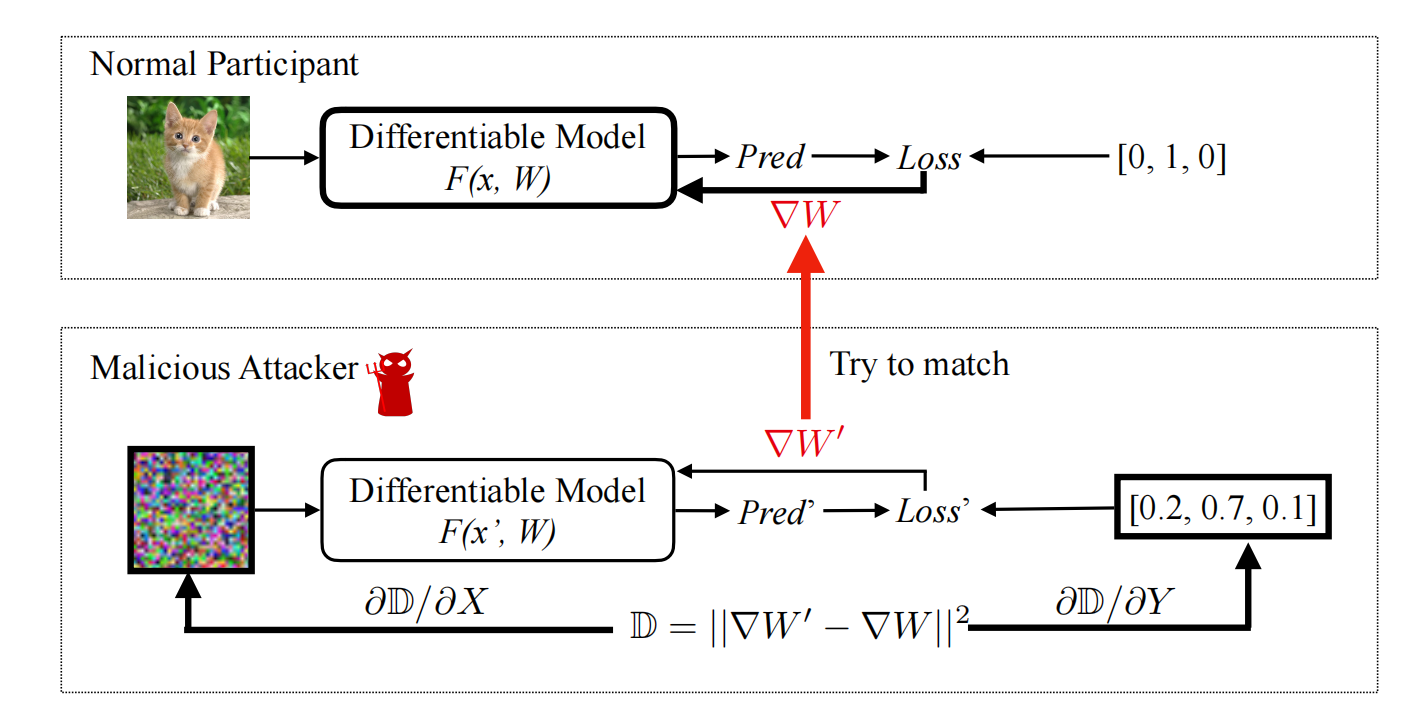
作者提出了一种优化算法来完成这一攻击:首先随机生成一种\(dummy \ inputs\),然后通过正常的梯度推导过程生成一个\(dummy \ gradients\),然后这个算法并不会像一般的优化算法一样去优化模型的权重,而是会优化dummy gradients和正常的梯度之间的“距离”,然后修改dummy inputs和输入标签,使得我们的伪数据越来越接近真实的数据,最终优化算法结束的时候,就是伪数据和真实数据完全匹配的时候。
同时,作者还指出梯度扰动,低精度和梯度压缩三种方法中,尺度大于1e-2的高斯噪声和拉普拉斯噪声有明显的作用,20%的梯度剪枝同样也能起到保护的作用,但是半精度的方法却不起作用。
Related Work
首先注意到的是,与“深度梯度泄露”相对应的是,浅层的梯度泄露。前人的研究表示从梯度中推断训练数据的信息特征是可能的。例如在语言任务中对训练单词的梯度就可以揭露哪些单词参与了训练集,我们明显可以察觉到,这类泄露是肤浅的,并且也没有过多的作用。
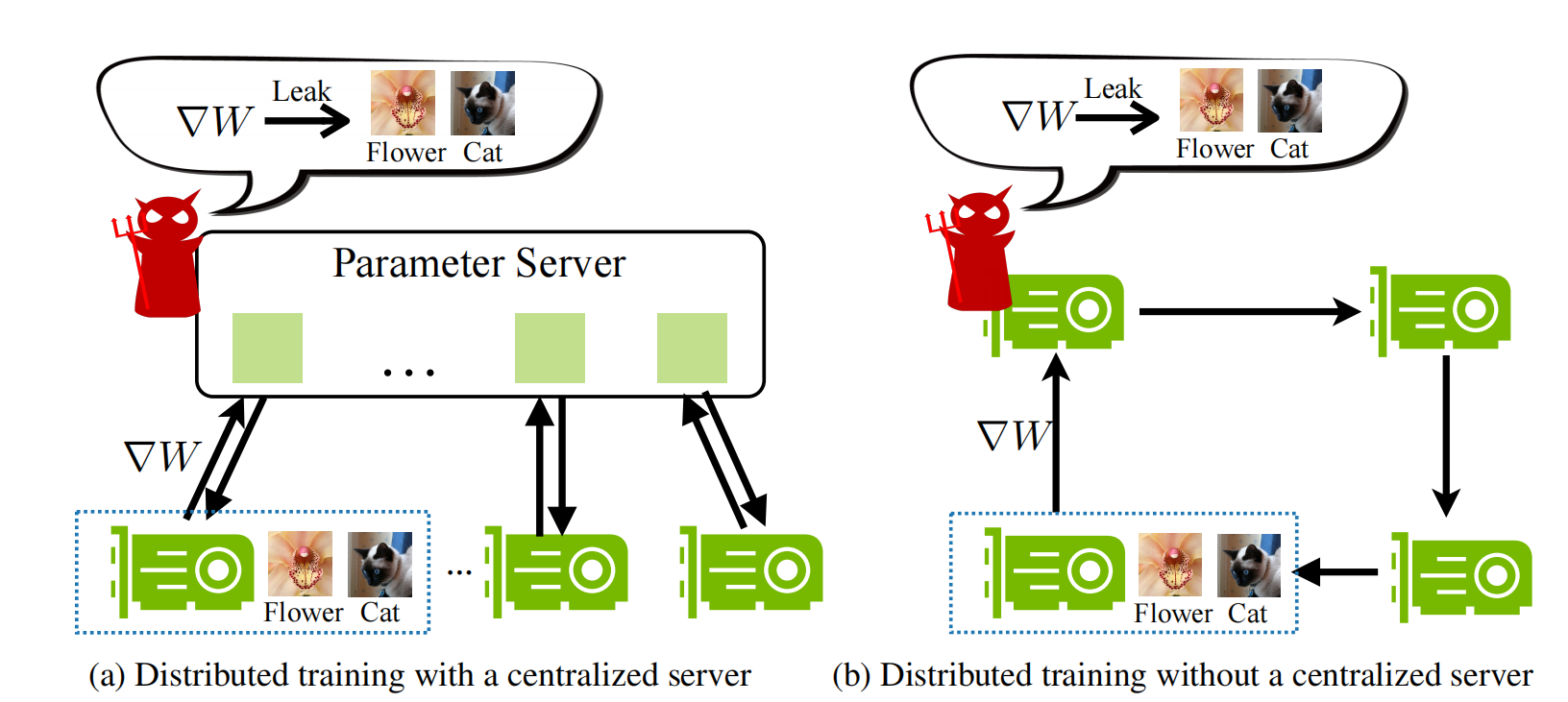
然后作者指出了分布式机器学习中一定会出现的梯度交换问题。并且指出了无论是哪种分布方式,去中心化或者中心化的分布式训练,都有可能存在“深度梯度泄露”的问题。
Method & Experiment
接下来我们来看看具体的方法。
首先我们关注传统的分布式学习方法,在第\(t\)轮训练过程中,第\(i\)方节点从训练集中选取\(minibatch(x_{t,i},y_{t,i})\)的数据来计算梯度,迭代的过程如下:
\[
\nabla{ W_{t,i} }=\frac{\partial{l(F(x_{t,i},W_t),y_{t,i})} }
{\partial{W_t} } \\
\nabla{W_t}=\frac{1} {N}\sum_{j}^{N} {\nabla{W_{t,j} } } \ ; \ \ \
W_{t+1}=W_t-\eta \nabla{W_t}
\] 以中心服务器式分布训练为例,中心服务器会获得\(k\)方的梯度数据,并且作平均聚合,然后反向调整。但是这里的优化算法不会按照这样的步骤来,它的目的是恢复数据。简单来说,就是先利用一个随机的“伪输入”和“伪标签”,得到一个“伪梯度”,然后将伪梯度和真实梯度之间的第二范数作为优化的目标(要求模型F二次可微,不过一般的神经网络模型都是二次可微的),不断地调整输入和标签值,使得“伪梯度”不断地接近真实梯度,最终就能够完全还原原输入。
\[
\nabla{W'} = \frac{\partial{l(F(x',W),y')} } {\partial{W} }
\\\
x^{'*},y^{'*} = \underset{x',y'} {argmin}\left \|
\nabla{W'-\nabla{W} }\right\|^2
\]
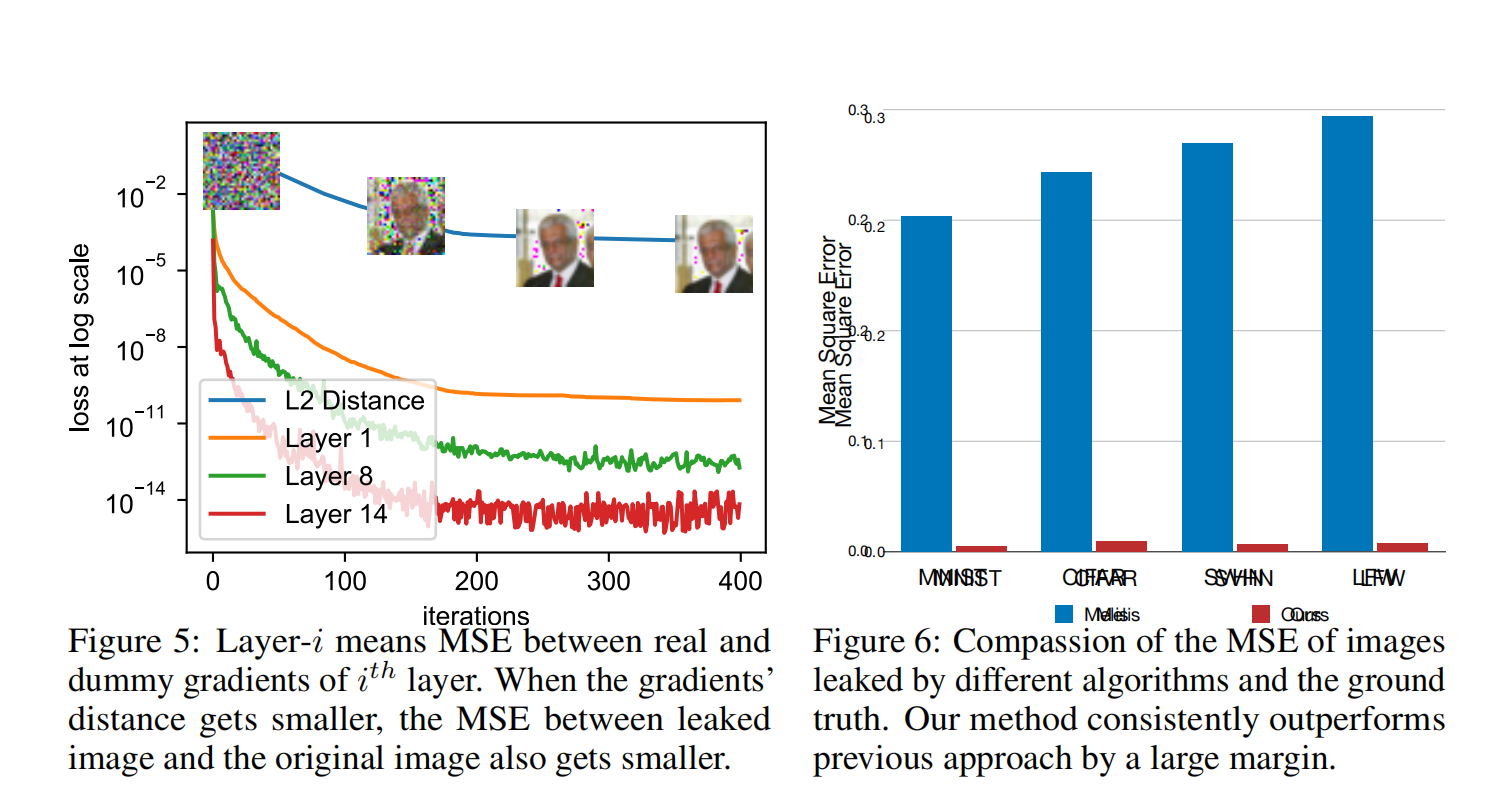
在迭代的过程中有可能出现的问题就是,这种做法对于batchsize等于1的数据集很有效,如果大于1,就会出现收敛速度很慢的情况。最后作者给出的方法就是单次更新只更新一个训练样本,这样就可以快速而且稳定的收敛效果。
\[
x^{'i \ mod \ N}_{t+1} \gets x^{'i \ mod \ N}_{t} -
\nabla_{x^{'i \ mod \ N}_{t+1} }\mathbb{D} \\\
y^{'i \ mod \ N}_{t+1} \gets y^{'i \ mod \ N}_{t} -
\nabla_{y^{'i \ mod \ N}_{t+1} }\mathbb{D}
\]

这听起来是一个天方夜谭,但是从实际的实验来看,效果出奇的好,除了个别像素伪影和顺序不同以外,几乎可以完全还原所有的源数据,比前人研究的方法也要明显占优。
Defense Strategy
如之前的介绍所示,作者给出了三种防御的方法,其中比较有效的就是使用差分隐私\((Differential \ Privacy)\)的方法来进行防御。言简意赅的说,就是给梯度加上一定的“扰动”,使得攻击者无法获得准确的梯度信息,也就没办法从梯度中还原准确的源输入。噪声的种类有高斯噪声和拉普拉斯噪声,防御的效果与噪声的种类之间没有特别明显的关系,但是和噪声的扰动尺度有明显的正相关关系。同时,作者也顺便验证了减少梯度精度的方法无法起到有效的防御效果。下面是实验结果的截图:
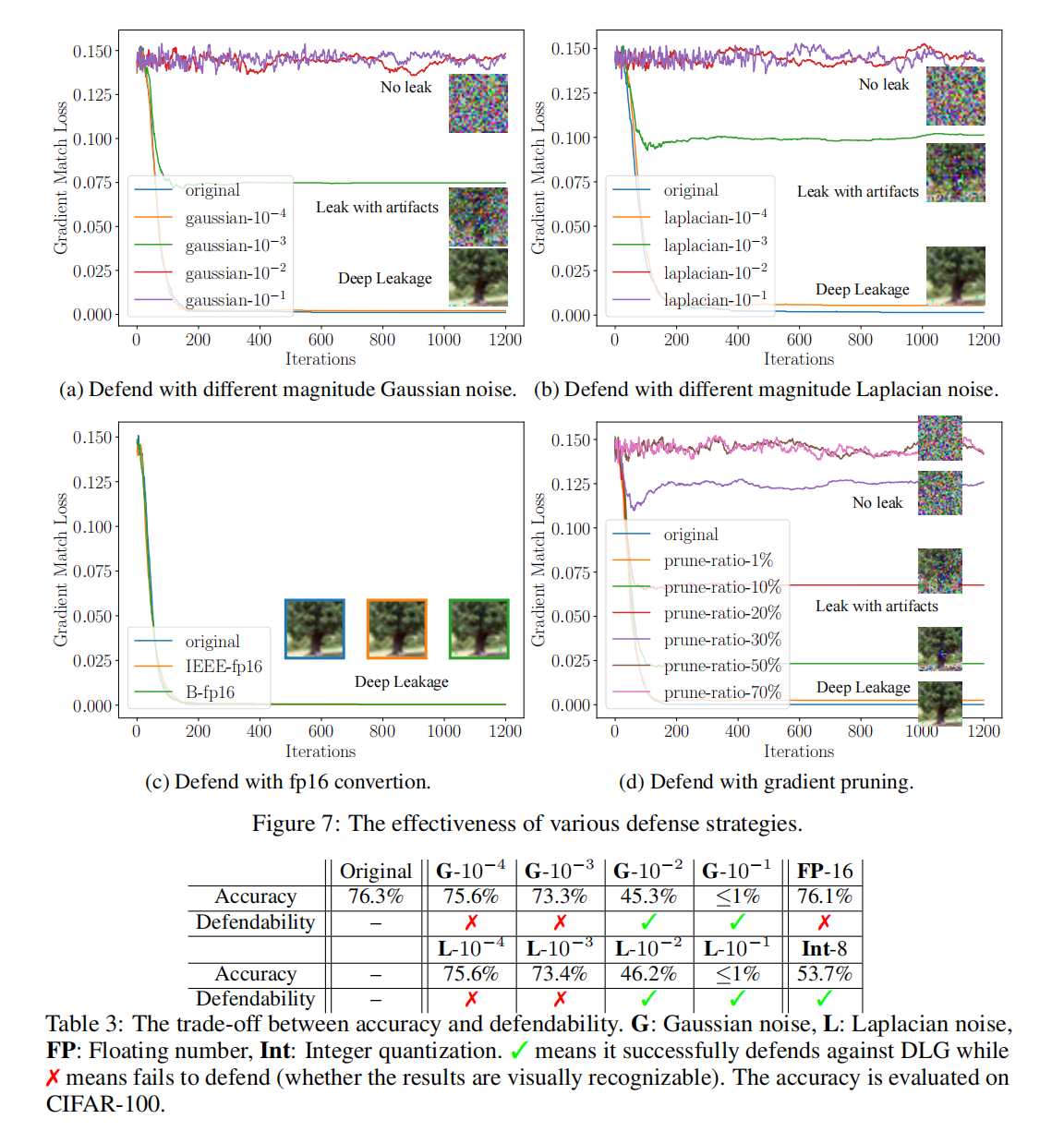
值得注意的是,尽管成功达到一定的干扰程度之后能够起到防御作用,但是\(acc\)率明显下降,已经开始影响收敛效率了。
最后,作者还指出了“梯度剪枝”\((gradients \ pruning)\)的方法是有效的。经过实验发现,能够让\(DLG\)还原的原始输入有明显偏差的情况下,修剪率应该在20%以上。但是最新的误差补偿技术和梯度压缩技术可以将梯度压缩300倍的情况下不影响\(acc\),远远高于阈值20%。所以可以得知梯度修剪的方法是有效的。
Conclusion
针对分布式训练的情况来说,在这篇文章的指出下,我们已经发现,“共享梯度,使得训练数据集留在本地”的做法已经不再安全了。仅仅通过简单的修改输入和标签,来靠近标准梯度的做法,就可以完全地还原源数据,这无异给分布式和协作式学习的模式带来了新的挑战。下一节我会用代码模拟一遍作者的实验,来还原\(DLG\)攻击。