知识蒸馏调研
生活本来沉闷,但跑起来就会有风。
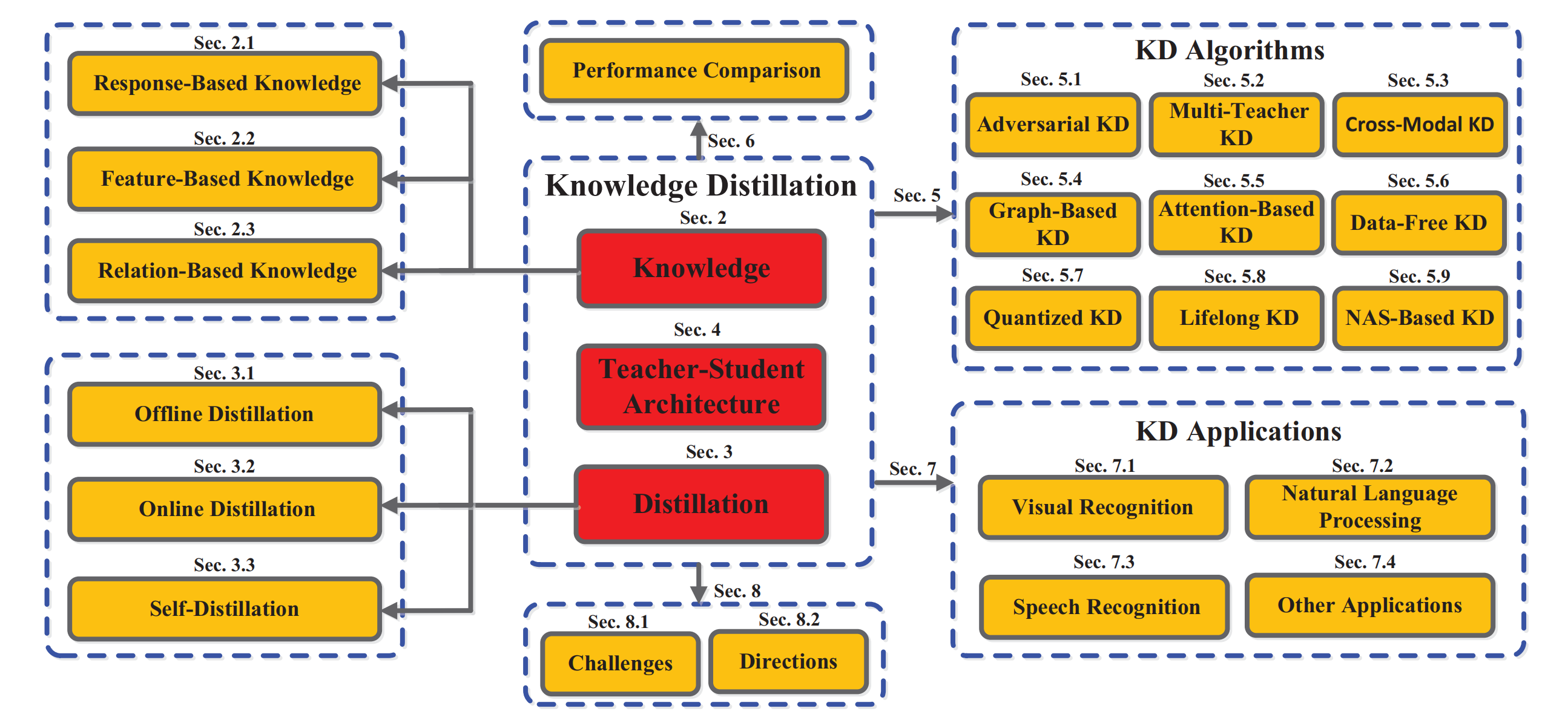
Knowledge Distillation: A Survey :这篇文章系统性的总结了关于知识蒸馏技术目前的所有发展技术,以及未来的展望。
我们按照这个框架的顺序来逐步调研知识蒸馏的技术。
Section2 Knowledge
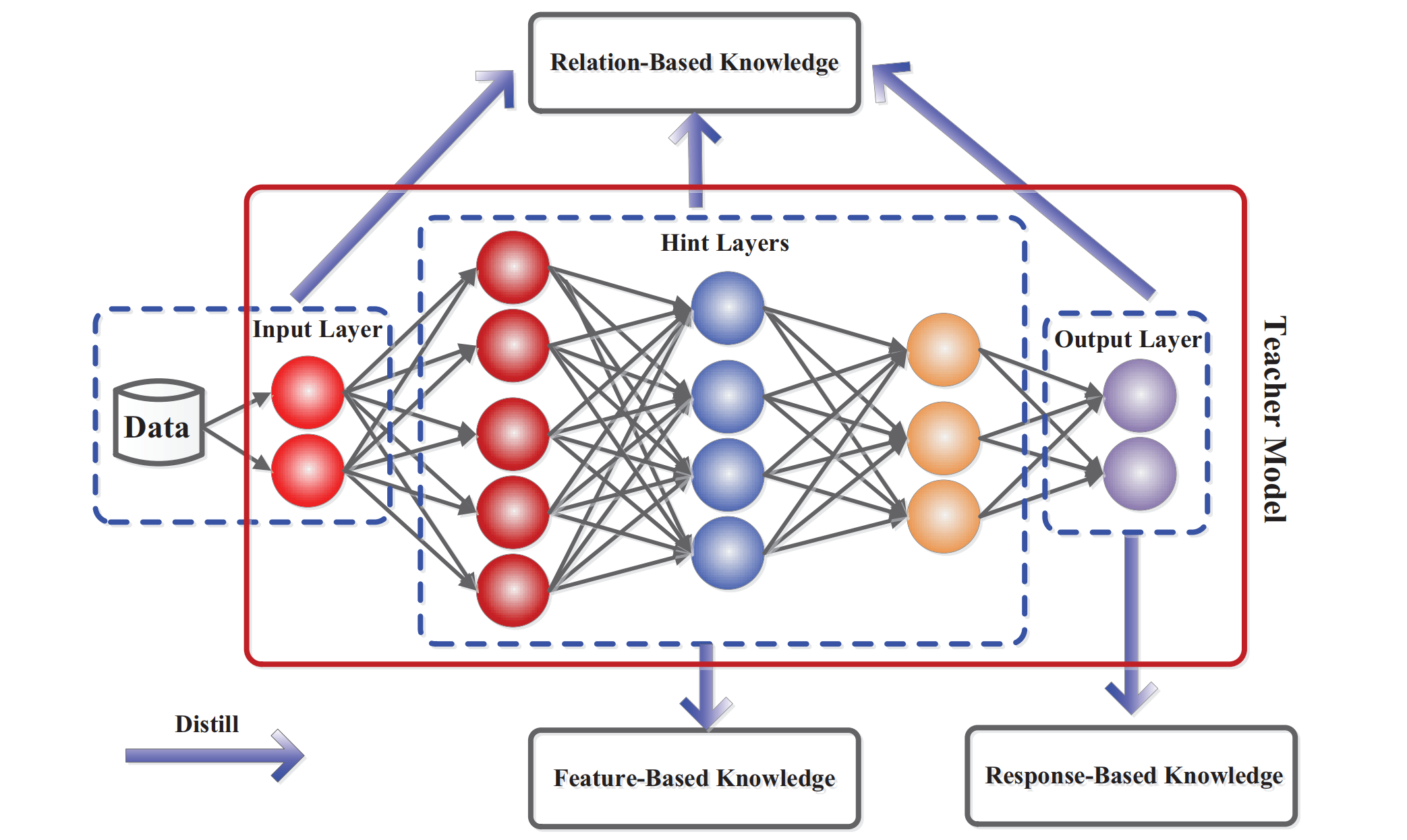
首先这张图给出了架构,知识蒸馏所蒸馏的知识层面,包括\(response-based, \ feature-based, \ relation-based\)三种层面。
Response-Based Knowledge
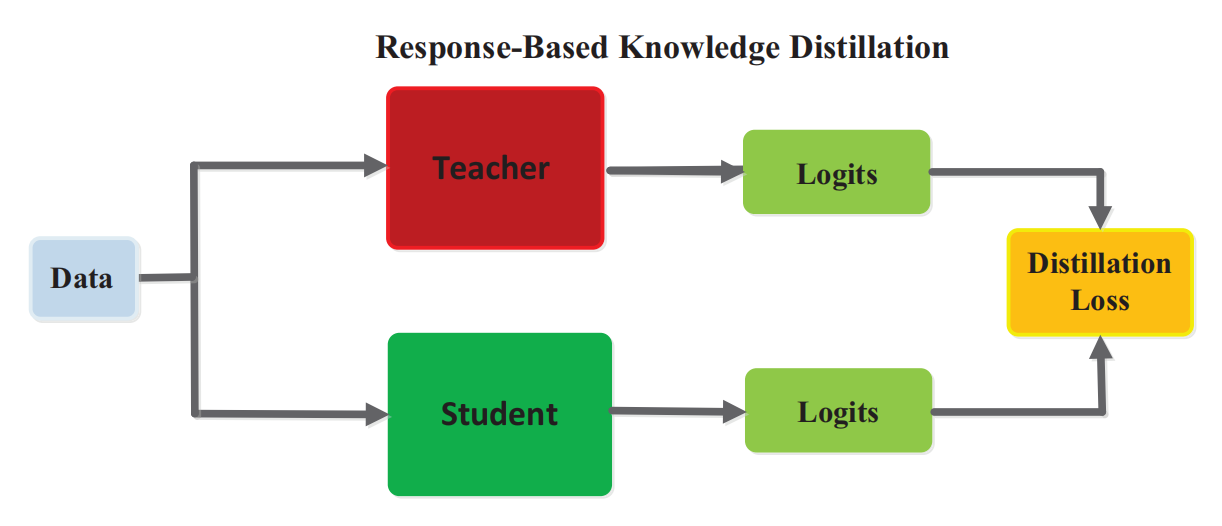
这个可以简单地通过这一张图来说明,student模型通过简单地模仿teacher模型全连接层的logits来学习知识。这里也隐含了所谓的\(dark \ knowledge\)。因为提取知识的过程必须要依赖最后一层全连接层的结果,所以只能用于 监督学习。
weaks
只能用于监督学习
无法获取教师模型中期的信息
Feature-Based Knowledge
主要思想:match the intermediate feature maps
some methods:
- using neuron selectivity transfer to generate "attention map"
- matching the probability distribution in feature space
- using "factors"
- route constraint hint learning , using outputs of hint teacher's hint layer
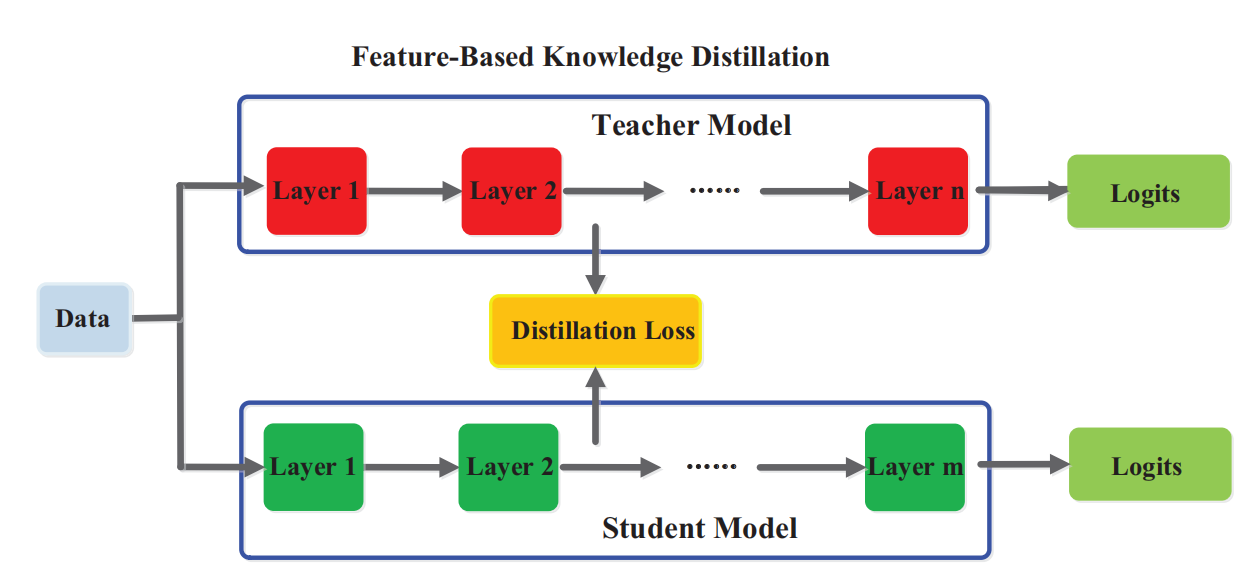
这是基于特征的知识蒸馏的bench流程,以及损失函数 \[ L_{F e a D}\left(f_{t}(x), f_{s}(x)\right)=\mathcal{L}_{F}\left(\Phi_{t}\left(f_{t}(x)\right), \Phi_{s}\left(f_{s}(x)\right)\right) \] 其中,当教师和学生模型的中间层参数、大小不一致时,需要使用\(\phi_t \ \phi_s\)转化函数。
weaks
- 如何选择合适的用于指导的隐藏层和被指导的隐藏层?
- 如何匹配不同大小、参数不同的隐藏层?
Relation-Based Knowledeg
无论是基于特征的还是基于输出的知识,都需要依赖于某个特定层的output。那么基于relation的知识就是在对不同层之间或者是数据样本之间的关联进行学习。
先是关于不同层之间的联系:
有人提出了FSP矩阵来研究两个特征映射对之间的关联
使用奇异值分解来学习知识
学生模拟教师模型中成对的隐藏特征层之间的信息流
loss function可以定义如下:
其中一对戴帽子的f分别表示一对来自教师或者是学生模型中的一对特征图。L依然是用来衡量教师模型和学生模型之间的差距。
\[ L_{R e l D}\left(f_{t}, f_{s}\right)=\mathcal{L}_{R^{1}}\left(\Psi_{t}\left(\hat{f}_{t}, \check{f}_{t}\right), \Psi_{s}\left(\hat{f}_{s}, \check{f}_{s}\right)\right) \]
另一种relation是基于数据样本之间的关系
- 通过instance relationship graph实例关系图
- 基于manfold learning(多形学习)
- 将数据样本之间的关系建模为概率分布
- 基于相关一致性correlation congruence的知识蒸馏,可以学到实例级别的信息和实例之间的关系。
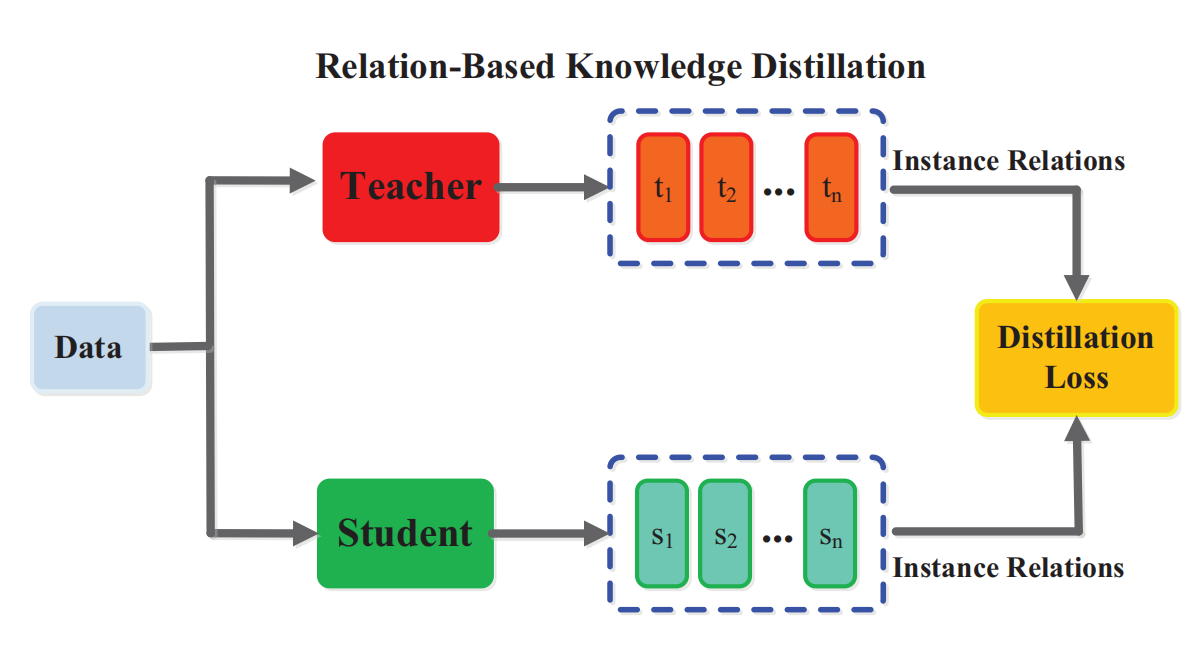
这是基于数据实例关系的知识蒸馏benchmark \[ L_{R e l D}\left(F_{t}, F_{s}\right)=\mathcal{L}_{R^{2}}\left(\psi_{t}\left(t_{i}, t_{j}\right), \psi_{s}\left(s_{i}, s_{j}\right)\right) \] 如上式所示,其中\(t\)和\(s\)分别来自老师和学生模型的\(feature \ representation\), \(\phi\)同样衡量两个特征表示之间的相似性,\(L\)衡量距离。
weaks
- 虽然现在提供了一些基于特征或者数据关系的知识类别,但是如何就关系合理建模依然值得研究。
Section3 Distillation Schemes
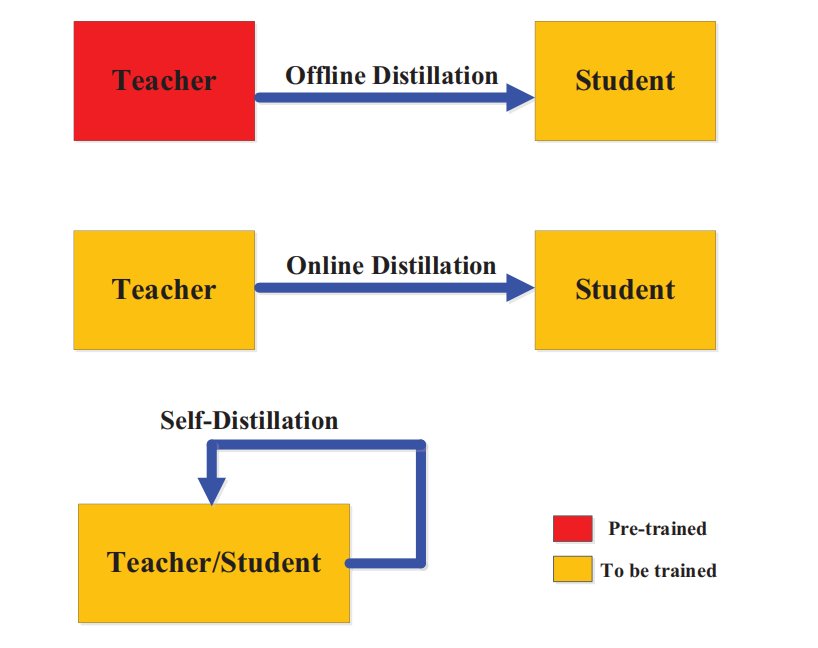
第三部分讲了现有的一些知识蒸馏的方式,根据教师和学生模型能否同步更新,区分为离线蒸馏,在线蒸馏,自蒸馏。
离线蒸馏:
单向知识蒸馏和双过程训练
无法避免大型的教师模型
在线蒸馏:
- 老师模型和学生模型的角色是相对的
- 多分枝结构,不同的分支代表同一个模型
- 共蒸馏
- 是一个单过程的端到端的并行训练
自蒸馏:
- 老师和学生使用相同的网络
- 将知识从深层次蒸馏到浅层次
- 一种无教师的蒸馏方案
- 采用数据增强的方法
- 对于老师和学生模型都单独使用自蒸馏方法进行优化
- 自蒸馏和在线蒸馏可以通过多知识转移框架进行一定程度上的融合
Section4 Teacher-Student Architecture
现阶段,许多教师和学生模型的参数等等都是预先设定的,导致了一些模型容量上的固有的差距。下面这张图大致介绍了都有哪些教师-学生模型架构。
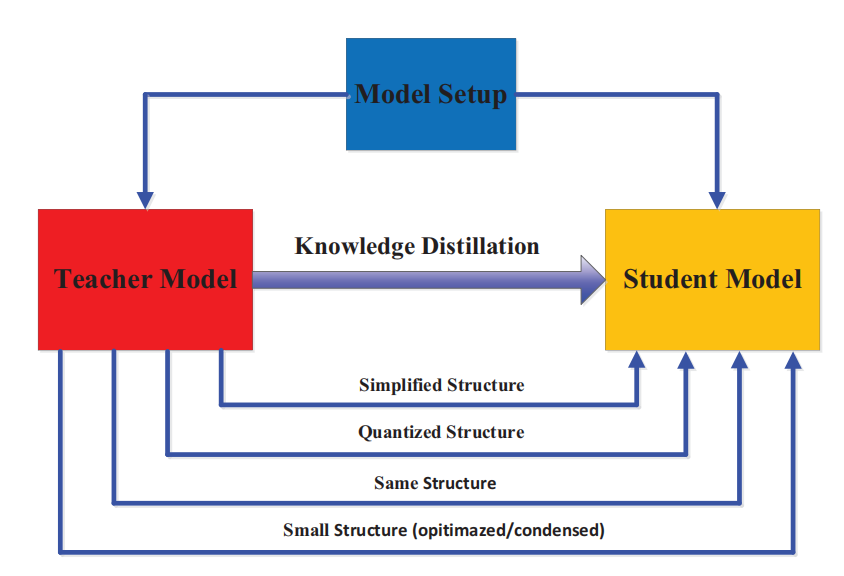
通常学生网络有两种:
- 更薄,更窄的教师网络
- 保持教师网络结构的量化版本
- 一个具有高效基本操作的小型网络
- 一个拥有优化全局网络的小型网络
- 和老师的网络相同
现阶段的一些研究方向
- 提出“teacher assistant”,助理教师模型来学习学习残差
- 将量化网络和知识蒸馏相结合,学生模型是小而量化后的模型
- 深度可分离卷积
- nas神经结构搜索
- 在教师模型的指导下,研究学生网络的结构和知识转移
Section5 Distillation Algorithms
最基本的蒸馏算法就是,match responsed-based knowledge例如logins,feature-based knowledge还有feature space的representations。下面是一些更加匹配的设计
对抗性蒸馏算法
- GAN生成数据,老师模型可以当作鉴别器,
- 老师作为生成器,GAN模型中的鉴别器确保学生能够一直模仿老师
- 老师和学生模型共同作为生成器,鉴别器用来加强在线知识蒸馏的效果。
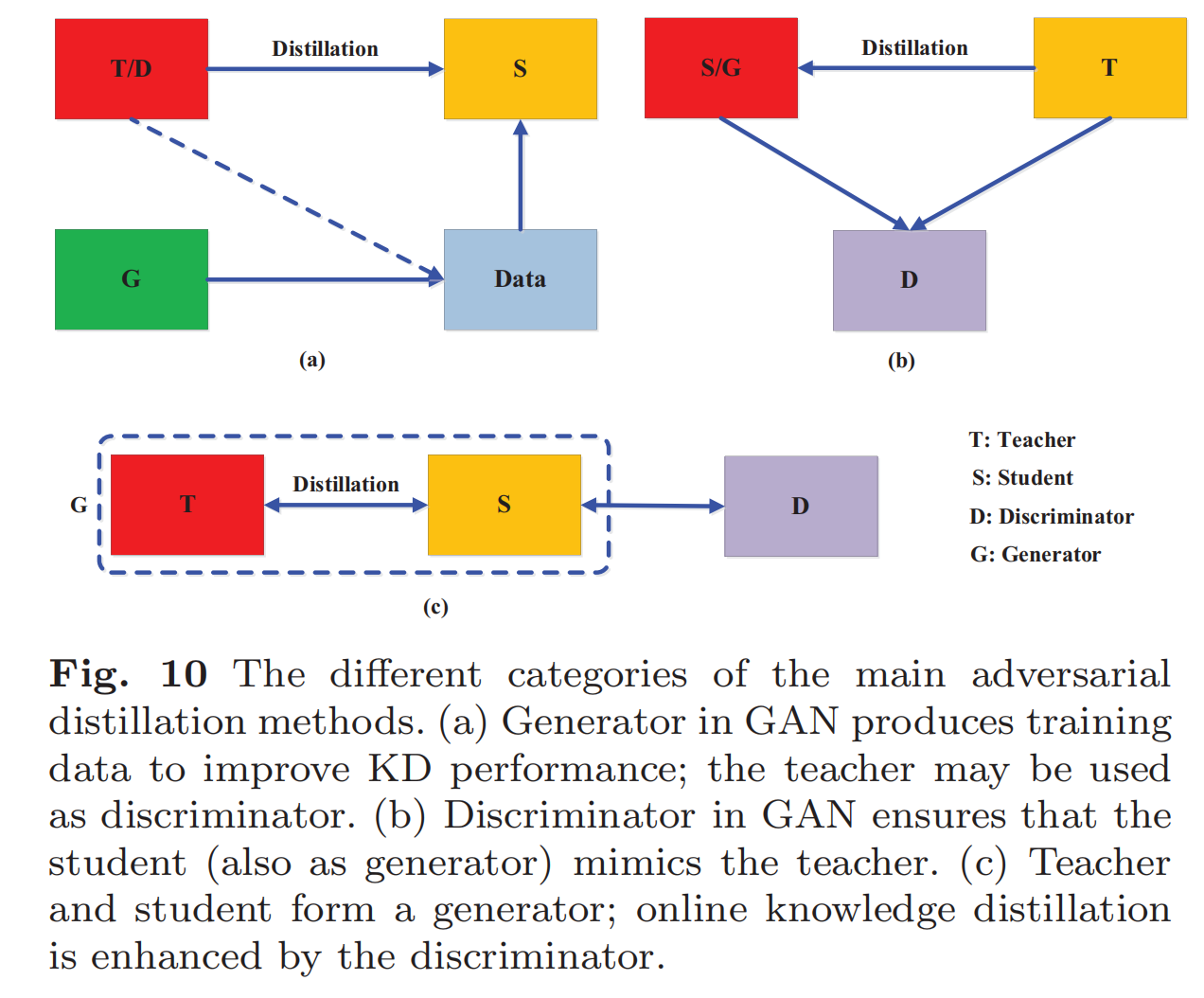
某些应用和探索:
- 鉴别器使用logits或者features来区分student和teacher的samples
- 使用未标记的数据进行知识转移
- 使用中间层监督的方法来缩小教师和学生模型之间的差距
gan的优点:
- 高效
- 可以克服有效数据不足的缺点
- KD也可以用来压缩GAN
多教师模型

- 简单平均来自每一个教师的logits或者feature
- 整合两种
- 重生网络:t步的学生是t+1步学生的老师
- 多教师模型的扩展可以用于知识适应领域,并且保护数据隐私安全
- 如何有效的整合来自不同教师之间的知识?
跨模态知识蒸馏
- using pair-wise relationship like RGB videos and skeleton-based human sequence
- 总结来说,就是将知识从一种模态转化为另一种模态的知识蒸馏,在视觉领域应用良好

基于图的知识蒸馏
- 研究数据之间的关系,而不是仅仅将数据样本里的知识传递给学生(relation-based)
- 一种是使用图作为教师知识传播的载体,另一种是使用图来作为教师传递信息的方式 (比如利用有向图来表达多模态之间的关系)

无数据知识蒸馏(Data-Free)
处于数据隐私或者是安全性、政策性的考虑
数据由GAN生成
通过教师网络的激活层传递数据
提出了深度反演deepinversion
zero-shot few-shot

主要还是利用预先训练的教师模型的特征层表示来生成新的数据进行训练
量化知识蒸馏

网络量化通过降低网络精度(如32位,降低到8位),减少了神经网络计算的复杂度
终身知识蒸馏
- 类似于人类的终身学习
- 知识蒸馏提供一种有效的方法来保留和转移所学到的知识
NAS-based 基于神经结构搜索的知识蒸馏
- 自动识别深度神经网络,并且自适应地学习神经网络的结构
- 在TGSA模型中,每一步神经网络的搜索步骤都用来模拟教师网络的中间特征表示。
- 自动识别深度神经网络,并且自适应地学习神经网络的结构
Section6 Comparison
Section7 Application
- CV领域
- NLP领域
Section8 Futures
四种压缩模型的方法,是否可以融合?
- parameter pruning and sharing
- low-rank factorization
- transferred compact convolutional fifilters
- knowledge distillation