神经网络处理文本情感分类
文本情感分类任务实验报告
计03 王文琦 2020010915
0. 完成情况
本次实验完成了以下成果:
- 使用改进后的TextCNN网络对文本情感进行分类预测。
- 使用单层RNN网络对文本情感进行分类预测。
- 使用双向多层LSTM循环神经网络完成同样的任务。
- 使用全连接神经网络MLP完成同样的任务。
- 不使用给定的word2vector分词模型,转而使用Albert大规模预训练神经网络进行同样的任务,并且对比与传统神经网络之间的差别。
代码已打包成zip,清华云盘链接:https://cloud.tsinghua.edu.cn/f/71d9a0461ff546cda8cc/?dl=1
1. 原理分析
首先,我们依次介绍模型的结构图以及原理实现。
1.1 TextCNN卷积神经网络
卷积神经网络被大量应用在图像处理上。我们知道图像通常是二维的(我们现在将忽略存在第三个“颜色”维度的事实),而文本是一维的。如何将一维的句列转化为二维的“可视化”的图像?我们注意到,训练的过程中并不是直接把每一个中文字符作为输入的元单位,而是先将一组中文字符(比如一个单词)转化为相应的词嵌入向量,然后再成批次地输入进入神经网络。所以我们可以让每一个单词的词向量作为横轴,句子的长度作为纵轴,“拼接”成为一个神经网络,如下图所示:

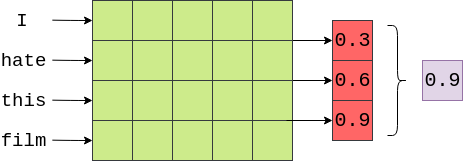
所以我们可以使用不同的\(filter \ size\)的过滤器,例如\([n, embedding]\)大小的过滤器,一次就会覆盖二维图像中的两行,也就是句子中的两个单词。过滤器中为每一个格子上的元素都配置了权重,每次移动,都会计算出所有元素的加权和作为输出。这样计算后,我们最终的输出拼接起来将是一个一维的向量,大小为\([1, sentence\ length - filter \ size + 1]\)。对于这一个卷积层的输出,我们采取一次最大池化,含义是取其中最情感最为丰富的维数加以池化、连接。

上图是\(TextCNN\)神经网络的结构示意图,限于篇幅,只选择了一种\(filter \ size\)和20个卷积核。在我们的实际模型中,选择了100个卷积核和\([3,4,5]\)三种\(filter \ size\)。最终的结果使用一个线性层来连接所有隐层的输出。值得注意的是,我们最后选择了一个输出而并不是二分类输出,最终的\(criterion\)选择的是\(BCELoss\)均方误差而不是交叉熵损失,越靠近0,就代表预测为\(positive\)的可能性更大;反之同理即可。下面我们所有的模型都是基于上述损失函数,将不再赘述。
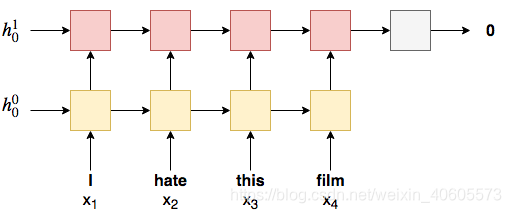
1.2 简单RNN循环神经网络
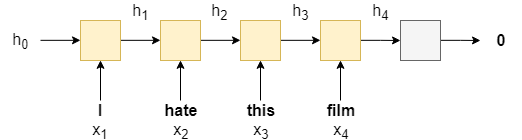
RNN的最基本的原理是,利用相同的神经元接受单词的序列,一次接受一个,生成一个隐藏状态。然后下一次的输出是由当前输入的单词和前一次的隐藏状态决定的。状态转移方程:\(h_t = RNN(x_t,
h_{t-1})\)。当我们有了最后的隐藏状态输出的时候,我们通过一个全连接层接受我们预测的信息,损失函数说明和之前一样。数据的预处理部分(词向量的嵌入)由word2vector模型给出。最后同样采取一个全连接层将隐藏层的所有输出转化为最终的单元素输出。
1.3 双向多层LSTM循环神经网络
在实验过程中我们发现单层RNN的实验训练效果并不好,而且存在着很明显的梯度消失\((vanishing \ gradient)\)问题。达到几个训练epoch之后就很难再有效果上的很大改进。为了改进,我们采用LSTM神经单元。简单来说,RNN在预测较近的单词的时候,会更有效,但是它很难记住更远处的上下文信息。在情感分类任务中同样如此。如果采用LSTM模块,因为内部采用更为复杂的四层非线性模块,通过一个\(cell\)的额外状态会更容易解决文本的长期依赖问题。状态函数为\((h_t, c_t)=LSTM(x_t, h_t, c_t)\)在下图中展现出了基本模型:
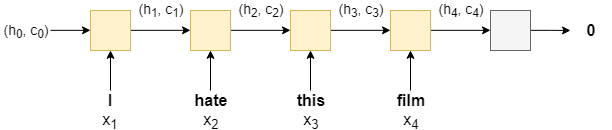
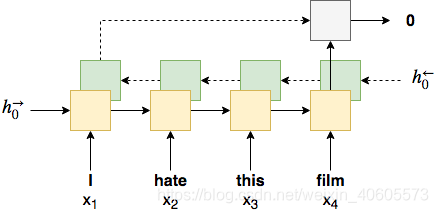
同时我们还采用了双向神经网络,一个从前往后输入句列信息,另一个从后往前输入句列信息,以二者的最终隐藏层输出叠加形成的张量作为最后的隐藏层输出。同时我们还可以加入多层RNN。当输入\(x_t\)序列时,低一层的RNN的隐藏层输出作为高一层的RNN的输入。取最高层RNN的最后一次隐藏层输出作为最终输出。在本次实验中,我们选择双层双向的LSTM网络作为训练结构。
1.4 MLP全连接神经网络
全连接神经网络在原理上非常简单,由若干全连接层和若干非线性层组成。通过模拟神经元之间的完全连接来构建复杂的非线性关系。在本次实验中,我们实现以下的全连接网络作为\(baseline\)用于对比参考,对于句子长度不一的情况,我们采用最大池化的方法进行降维。(限于篇幅,图中参数与真实训练不同。真实训练过程中选取\(input \ dim = 50, hidden \ dim = 256, output \ dim = 1\)):

1.5 Albert大规模预训练模型
除了以上基于word2vector的模型以外,本次实验还实现了大规模预训练模型\(albert\),相对于之前的模型作为另一个\(baseline\)。word2vector是一个上游模型,将稀疏的词向量转化为稠密的语义向量,但是却只能是静态表征。我们知道,同一个词在不同的上下文语境下是有着不同的含义的,比如“苹果”公司的苹果和我们日常所吃的苹果就是不同的含义,但是在word2vector中他们有着相同的词向量表示,这显然有着继续优化的空间。
Bert模型是针对语言训练的一个双向Transformers模型,我们可以利用Bert的预训练模型。首先加载预训练模型,利用单词的上下文信息作特征提取,注意这里,CNN是在一个特定的划定窗口对语句做特征提取;RNN是分别单独利用上文、下文作特征提取,但是Bert模型能够利用每个单词完整的上下文信息,动态调整词向量,这与静态的word2vector完全不同。接下来我们只需利用其输出的特征向量连接下游的任务即可,也即\(Fine-Tuning\)过程。在本次实验中,因为运算资源的限制,我们采取了voidful/albert_chinese_small的微缩版Bert模型,在预训练模型之后,再添加一个全连接层输出结果。

2. 训练过程与实验结果
训练过程中,我们采用了wandb可视化的方法,将需要展现的参数例如训练准确率和损失函数的输出动态展示在面板上,并且横向比较不同的模型之间的性能。从训练的结果就可以明显看出,在五个模型中,统一训练30个epoches的情况下,Bert模型的收敛速度最快,训练集上的准确率也最高,超过99%;相较来说,MLP模型的表现最差,在前几轮epoch就几乎已经收敛,最终准确率也没有超过80%;TextCNN和LSTM的效果相近,几乎可以达到95%左右;单层RNN模型的效果位于MLP以上,不如TextCNN和LSTM,且损失函数也出现了较大的波动情况。


最终的测试准确率以及算出的\(F-Score\)如下表格所示:
| Model | Test Accuracy(%) | F-Score |
|---|---|---|
| CNN | 81.75 | 0.8101 |
| 单层RNN | 81.84 | 0.8091 |
| 双向多层LSTM | 84.28 | 0.8432 |
| MLP | 76.69 | 0.7637 |
| AlBert | 91.01 | 0.9319 |
3. 参数调整过程
在参数调整的过程中,我尝试了使用wandb+sweep的方式进行自动调参,但是鉴于每次训练运行的时间过长,仅在textCNN上做过实验,因为参数搜索的空间非常大,不同实验之间相差无几,在短时间内无法得到最优解。
# 超参数搜索方法,可以选择:grid random bayes |
所以我在实验的过程中采取了经验调参法。关于batch_size,因为句子的长短不一,采取padding或者truncate手段会导致文本信息不全,经过实验显示设置batch_size为1较为合适(除去AlBert模型采用了16,因为模型的对齐性要求以及大规模模型需要batch更大效果更好);关于优化器,sgd的稳定性较差并且学习率无法动态调整,容易出现震荡,故选择adam;dropout采用半丢弃,即0.5效果较好,若选择高丢弃率(0.9),容易导致收敛时间长;epoch统一选择30轮,所有模型基本都能收敛;learning-rate一般初始值设为0.001,Albert模型初始值设为0.0001,因为模型的提取能力很强,学习率需要降低,否则会很容易出现震荡情况。
4. 模型表现差异
模型结构层面的差异已经在第一部分给出。在表现方面,我们可以从最终测试的结果看到,RNN和CNN的表现所差无几,而MLP的表现则较差。实验后分析原因可知,我在MLP的数据输入处理上,对输入词嵌入向量事先采用了一层平均池化进行降维,这可能大大降低了句子中所包含的有效信息含量。LSTM神经网络则大大提高了对上下文特征的捕捉能力,在测试准确度上也有所提升。而采用了预训练模型和Fine-Tuning方法的AlBert模型的表现则超越了传统模型,说明动态获取词在上下文之间的含义,从而得出语义向量比直接使用静态的效果要好。
5. 问题与思考
- 可以每一轮epoch设置validation数据集进行验证,保存效果最佳的模型,舍弃出现过拟合后效果下降的模型;也可以判断当前准确率低于某一个阈值的时候强制停止训练。我采用的是前者。前者可以直观观测在验证集上的准确率变化,全局选择,但是实验时间较长;后者实验时间段,灵活方便,但是模型之间不方便横向对比。
- 一般用均匀或正态的零均值分布来初始化线性层、卷积层的权重矩阵和偏置,根据系数的不同,又分为 xavier 的均匀、正态分布,kaiming 的均匀、正态分布。xavier 的分布适用于激活函数是 tanh 的初始化,不太适用于 ReLU。而 kaming 则非常适用于带 ReLU 激活函数的地方。PyTorch 里的线性层的初始化为均匀分布 U(-sqrt(1/in), sqrt(1/in))(a = sqrt(5) 的 kaiming 分布,in 为矩阵的第二维大小)。在本次实验中,我尝试了正态分布初始化,发现效果并没有明显的变化,故统一采用Pytorch默认初始化权重。
- 一般有
Batch Normalization和Dropout两种方法。BN方法可以有效地避免两种极端情况:梯度爆炸和梯度消失,但是容易延长收敛的时间;Dropout方法比较方便快捷,效果也很不俗。本次实验我采用的是Dropout方法。 - MLP网络结构简单,方便GPU加速计算,但是输入维数固定不够灵活,参数数量和效果不成正比。
- CNN网络结构易于理解,对于局部特征提取效果优秀,但是对于全局信息完全无法获知。
- RNN网络可变性较强,如果使用LSTM变体和双层双向等方法,对于全局信息有较好的把握,但是训练时间很长,收敛速度慢。
6. 心得体会
因为实验室正在研究的课题是联邦学习相关,也需要书写一些机器学习的代码,这次大作业让我对整个机器学习的过程(Pytorch代码层面)有了比较全面的认识,也对实验室的工作有很大的帮助。平心静气地说,无论原理是否理解,当代信息专业的学生都应当学会机器学习的思想和它的应用,在很多领域它确实是一个非常优秀的工具。